
สวัสดีคร้าบบบ เปิดมาด้วยชื่อบทความที่ไม่ค่อยอภิรมณ์เท่าไหร่(ศัพท์อะไรนิ 555+)
เคยไหมครับที่เวลาเราได้ข้อมูลมาจาก Data Source สักที่นึงแล้ว Data นั้นทำให้ตัวเรารู้สึกว่า
- ไม่อยากทำ
- ไม่อยากเปิด
- ไม่อยากยุ่ง
- ทำไมมันมั่วได้ขนาดนี้
- เทเลยได้มั้ย ???
นี่แหละครับ เราเรียกมันว่า Dirty Data หรือข้อมูลที่มัน Messy สุดๆ (ไปฮะ ศัพท์ทับศัพท์ไปเรื่อยๆ 555+)
Data แบบนี้เป็นสิ่งที่หลีกเลี่ยงไม่ได้เลยจริงๆครับ สำหรับคนที่ทำงานสายนี้ งานที่ต้องเรียกว่า Data Cleaning จึงเป็นงานที่ไม่ว่าจะชอบไม่ชอบยังไง
“แกก็ต้องทำ 😂”
หน้าตาของ Dirty Data
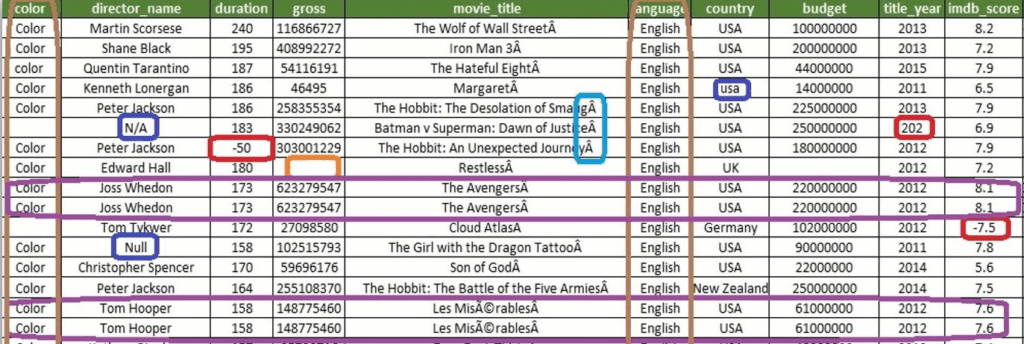
ให้ลองดูจากภาพด้านบนนะครับ จะมีจุดที่ highlighted เอาไว้ นี่แหละครับ คือสิ่งที่เป็น noise ของเราในการทำ Data Analytics มากๆ ผมจะค่อยๆไล่ตัวอย่างไปทีละอันนะครับ
(หายใจเข้าลึกๆ)
- ข้อมูลไม่เต็ม
- ข้อมูลเป็นค่าว่าง(เป็นค่า N/A)
- ข้อมูลซ้ำแถว
- ข้อมูลซ้ำคอลัมภ์
- ตัวอักษรเอเลี่ยน
- พิมพ์เล็ก พิมพ์ใหญ่
- ข้อมูลหายไปบางส่วน
- ข้อมูลดูท่าละไม่น่าใช่ ไม่ล้อไปกับความเป็นจริง
8 ข้อผมว่าก็พอละ เพราะว่าถ้าผิดแบบนี้ 8 ข้อ สัก 10 Dataset เท่ากับว่าเราต้องทำ Cleaning แบบนี้ 10 รอบ ซึ่งทำให้เราหอบแห่กๆได้เลย (หัวไม่ปวด แต่ทรมานมากฮะ จากประสบการณ์ 🤣)
จัดการข้อมูลที่ไม่ Fill
วิธีการจัดการกับข้อมูลที่ไม่ได้ถูก Fill นั้นง่ายมากครับ นั่นก็คือ “Fill” มันซะเลย 555+ เป็นไง ง่ายมั้ย ??
แต่ที่ต้องคิดสักหน่อยก็คือเราจะต้อง “Fill อะไร ?” นั่นแหละครับ
ถ้าเกิดว่าข้อมูลใน Column นั้นถูก fill มาแล้วด้วยคำว่า Color เราจะไปฉีกใส่คำว่า “Colour” มันก็ยังไงอยู่ใช่ไหมล่ะ ? เพราะฉะนั้น อย่าลืมดูบริบทของข้อมูลด้วย ว่าเค้าเปิดมายังไง และปิดยังไง
จัดการข้อมูลที่เป็น N/A
หลายคนอาจสับสน ระหว่างข้อมูลที่ยังไม่ได้ Fill กับข้อมูลที่เป็น N/A
วันนี้ผมจะมาเฉลยยยย…
N/A ย่อมาจาก Not applicable คือถ้าแปลเป็นไทยคือยังไม่พร้อม ไม่เกี่ยวข้อง ไม่เป็นเหมือน standard ของข้อมูลชาวบ้าน
แต่ถ้าเป็น un-fill คือข้อมูลที่ตั้งใจลืม หรือลืมจริง หรือไม่ได้ใส่มาจากทาง User ที่เป็นคน input เลยครับ
วิธีจัดการกับข้อมูลที่เป็น N/A นั้นก็คล้ายกับ Fill เลย ก็คือ “เติมมันลงไปซะ” ไม่ว่าจะเป็นค่านั่นค่านี่ อาจจะเป็นค่า min, max, mean, mode, median หรืออย่าง 0 ก็ถือว่าเป็นค่านึงเหมือนกัน เพียงแต่มีค่าเป็น 0
ซึ่งส่วนใหญ่แล้วก็ base ตามแต่องค์กรหรือ policy เราเองเลยก็ได้ครับ ว่าเราจะจัดการค่านี้ด้วยอะไร ส่วนใหญ่แล้วที่ผมเจอก็คือใส่เป็น average หรือค่า mean ไปเลยฮะ
หรืออีกอันซึ่งก็อาจจะเห็นได้บ่อยก็คือ …. “ลบมันทั้ง row” นั่นเลย 55555
ซึ่งการลบนี่ก็ต้องดูความเหมาะสมอีก เพราะถ้ามี 10 คอลัมภ์ แล้วทั้ง row นั้น มี N/A แค่ 1 แต่ field ที่เหลือสามารถเอาไปคำนวนนู่นนี่ได้ การลบทั้ง row ก็คงจะไม่เหมาะสมเท่าไหร่น่ะครับ
จัดการข้อมูลที่ซ้ำ (แถว + คอลัมภ์)
เอาหน่า ชีวิตคนเรามันก็ต้องมีการ double กันบ้าง ขนาดรถที่ขี่ยังมีเบิ้ลเครื่องเลย (เอ้ะ เกี่ยวอะไร เดี๋ยวๆ 😂)
การ input ข้อมูลซ้ำเป็นเรื่องปกติมาก ในการ collect data ครับ โดยเฉพาะ ถ้าเป็นการ input ข้อมูลจริงๆ จากคนจริงๆ ที่ไม่ได้มีระบบอะไรที่จะ prove ว่าคนๆนี้ได้ใส่ข้อมูลไปแล้ว
วิธีแก้ปัญหานี้ก็ง่ายๆเลยฮะ หลายๆ tool มักจะมีฟังก์ชั่นที่ชื่อว่า remove duplicated อยู่แล้ว จัดการได้เลย
หรืออีกอัน จะ sort ข้อมูลก่อนแล้วให้มันเรียนตามตัวอักษร แล้วจะ prove ตัวอักษรเองดูว่าอันไหนไม่เข้าพวกใดๆก็ไม่ว่ากัน ถ้าขยันนะฮะ
แต่อย่าเลย เหนื่อยป่าวๆ 555 ไปเหนื่อยข้างหน้าเอาเถ้อะๆ
ตัวอักษรเอเลี่ยน
อันนี้ง่ายมากที่จะ detect เลยครับ แต่อาจจะต้องใช้เทคนิคในการ sorting ข้อมูลสักนิดนึง หรืออาจจะดึงข้อมูลที่เป็นค่า unique มาก็ได้ แล้วเดี๋ยวก็ค่อยใช้ function นี้
find & replace
ค้นหาแล้วแทนที่มัน
อาจจะเป็นค้นหาคำที่เราต้องการจะลบ แล้วก็แทนที่ด้วยค่าเปล่าเลย ให้ถือเป็นค่า “ว่าง” ไปหลังจกตัวอักษรเอเลี่ยนตัวนั้น
ผมบอกเลยว่าฟังก์ชั่นนี้แต่ก่อนส่วนตัวคิดว่าไม่เห็นจะมีประโยชน์เลย แต่พอได้มาทำงาน Data คือได้ใช้เยอะจริง ได้ใช้บ่อยๆด้วย ฮ่าๆ
ขอโทษที่ดูถูกแกเกินไป~
พิมพ์เล็ก-ใหญ่
อันนี้ยากในบาง tool และก็ง่ายมากในบาง tool เลย
อาจจะดึงข้อมูลมาแล้วก็ใช้สูตร lower() แล้วก็เอาไปแทนที่ตัวเก่าก็ได้ หรือถ้าเป็นใน python แค่ใช้ .str.lower() แบบนี้ ในชื่อ header แล้ว run ดู
เปรี้ยงเดียว
Data อันใหม่ของเราก็มีชื่อ header หรือชื่อ column ที่เป็นตัวพิมพ์เล็ก-ใหญ่ ตามที่เราต้องการแล้ว
ส่วนตัวแล้วผมสนับสนุนให้ทำนะครับ ทำให้มันเป็น standard เลย เพราะว่าถ้า clean เสร็จแล้ว ถ้าจะต้อง query ข้อมูล หรือทำ analysis ใดๆ บางทีมันจะมี bug เล็กๆบ้างที่ tool ที่เราใช้มันจะไม่อ่านชื่อ column เรา
หรืออาจจะเป็นเรานี่แหละ ที่จำไม่ได้ว่าใช้พิมพ์เล็ก หรือพิมพ์ใหญ่หว่า
(ส่วนใหญ่จะเป็นข้อหลัง)
ข้อมูลหายไปบางส่วน
ไปตามหามาครับ
อันนี้ไม่ได้กวนเลย จริงๆ 555 ไปตามหามาเถอะครับ ถ้ามันไม่ได้เยอะขนาดนั้น เพราะถ้าข้อมูลที่มันหายไปมีปริมาณข้อมูลที่เยอะแล้วล่ะก็
การทำ Analysis หลังจากนั้นมันจะเละไม่เป็นท่า
หรืออย่างถ้าจะเอาข้อมูลไปทำ Model ทาง Data Sci เนี่ย มันจะเป็น Model ที่เพี้ยนๆเอา เพราะข้อมูลมันไม่สมบูรณ์น่ะครับ
หรือถ้าไม่ได้จริงๆ อีกวิธีที่ผมใช้บ่อยๆก็คือ
“ลบทิ้ง ทั้ง row เลย”
และถ้าถึงเวลาที่ต้องทำ Report ล่ะก็ ผมก็จะมีหมายเหตุที่บอกไว้ด้านล่าง หรือตั้งแต่เริ่มเลยว่าข้อมูลนี้มีความไม่สมบูรณ์กี่ % เมื่อเทียบกับข้อมูลทุก field แล้ว
(เอาไว้ป้องกันตัว ตอนมีคนมาเถียงน่ะครับ)
ข้อมูลแปลกๆ ดูไม่ค่อยสมจริง
ดูบริบทของข้อมูลก่อนครับ
อย่างเช่น ถ้าเลขมันโดดขึ้นมาเป็น 1000% เลยเนี่ย มันเกิดจากการใส่ผิด หรือว่ามันคือความจริง ?
อาจจะมียอดขายสูงผิดปกติ เพราะลูกค้าเข้ามาดูเยอะ งี้
ต้องเช็คก่อนครับ
เพราะข้อมูลนี้จะมีผลกับ outlier ของ data เราอย่างมาก
ตอนทำ Analysis อาจจะไม่ต้อง include ข้อมูลพวกนี้เข้าไป
บริบทของข้อมูลนั้น จริงสำคัญมากๆจริงๆครับ เพราะไม่งั้น ผมลบทิ้งไปแล้ว (อย่าลืมดูธรรมชาติของธุรกิจ หรือที่มาของข้อมูลที่เรากำลังจะทำ Analysis ด้วยเด้อ)
สรุป
ถือว่าเป็นบทความชิวๆต้อนรับวันหยุดประจำสัปดาห์ละกันนะครับ (ไม่ได้เขียนนาน) อาจจะเป็นเหมือนกับการได้ review การทำงานของเราไปในตัวด้วย เรื่องที่เราเอา data analytics ไปประยุกต์ใช้กับงานที่ทำอยู่ หรือจะเป็นคนที่กำลังหาความรู้ด้านนี้ ก็หวังว่าบทความนี้จะมีประโยชน์นะฮะ
สุขสันต์วันหยุดล่วงหน้านะครับ!
Leave a Reply